Analyzing Logs with the Linux Sort Sandwich
Analyzing Logs with the Linux Sort Sandwich
In a perfect world, we’d always have access to a nice pretty graphical interface where all our data is co-located and happy. Unfortunately, that’s not always the case. Here I’ll walk through a really simple way to help with filtering or sorting through text-based logs using built-in Linux tools.
TL/DR - The Result Up Front!
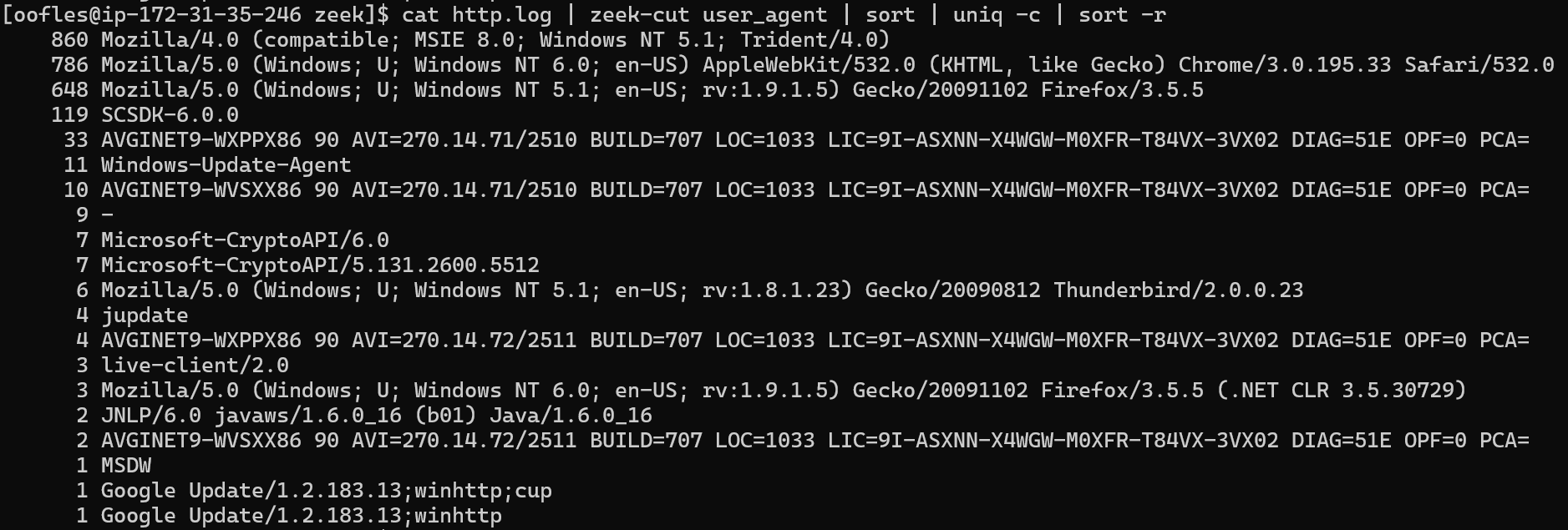
Using Zeek (Bro) logs as an example, here are the top user-agents seen throughout all HTTP conversations:
cat http.log | zeek-cut user_agent | sort | uniq -c | sort -r
Reading the Logs
In the example, I’ll be using Zeek logs which is an amazing open-source tool for analyzing network conversations. (Reference: https://zeek.org/) However, the same technique can be used for any text-based logs since we’ll be using built-in Linux tools!
Let’s start by simply reading the file with the cat (or concatenate) command:
cat http.log
Gross! Let’s try a different approach:
less -S http.log
Ah, much cleaner - now we can see what we’re dealing with! Zeek logs are organized by tab-delimited columns. It makes lining up the data with their categories a little bit more complicated, but now we can see all kinds of useful data we might want metrics on.
Extracting a Field or Column
Zeek makes this process extremely easy if you know the field name, so we’ll look at that first. The zeek-cut command will remove all columns and additional data points except the column you’ve specified.
cat http.log | zeek-cut user_agent
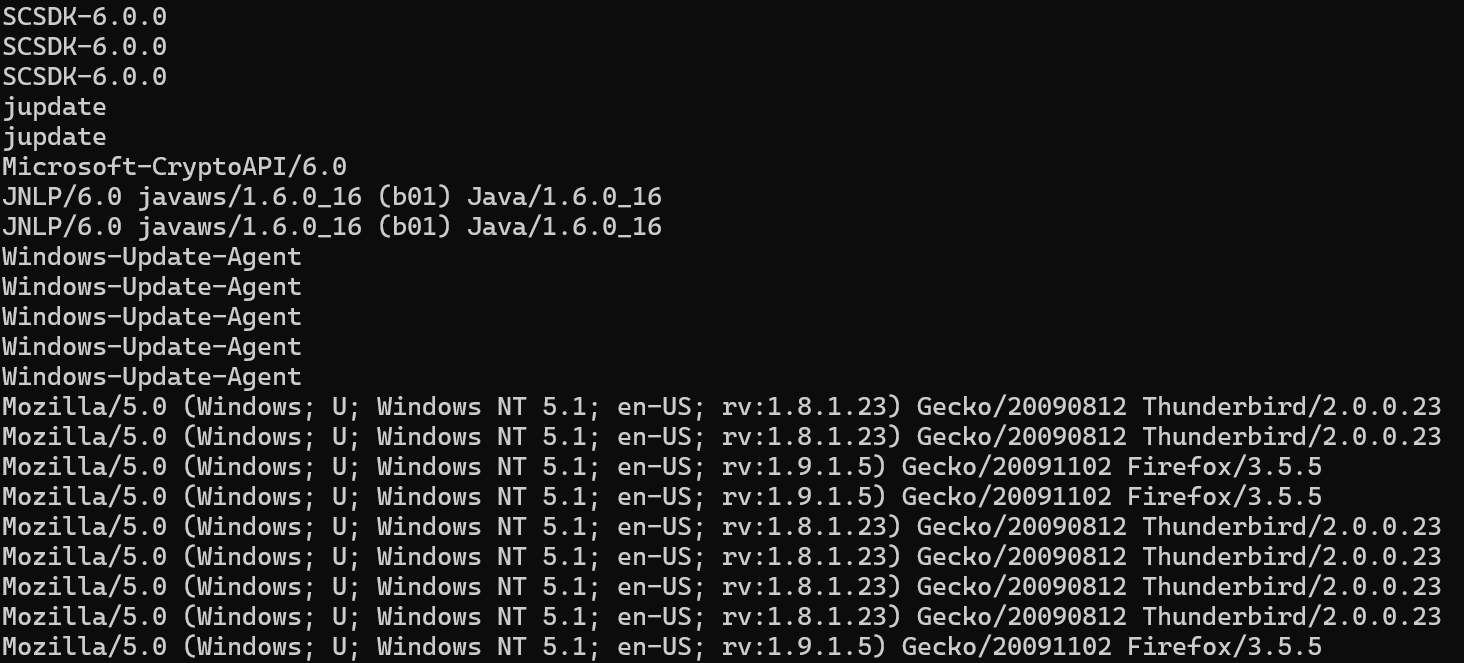
Awesome! But what if you aren’t using Zeek? No worries - the cut command does the same thing, but allows you to specify a field (or column) number and any delimiter!
Same approach, but using cut:
cat http.log | cut -f 13 -d " "
-
-f= allows you to specify a field (or column number). In this case, I just counted and found that the user-agent field was the 13th column from the left. -
-d= allows you to specify a delimiter. Since Zeek logs use tab delimiters, we actually don’t need to specify anything andcutwill automatically split it up properly! However, the delimiter can be anything you want it to be (dots, spaces, colons, semi-colons, etc.)
Sort Sandwich!
Now that we’ve extracted the targeted field, we can use the “sort sandwich” to quick table of counted unique values.
-
sort= sorts lines of text alphanumerically (no surprise here!)-r= reverses the sort so higher numbers appear on top
-
uniq= de-duplicates lines of text and reports only unique values-c= counts the number of times that unique value was seen
cat http.log | zeek-cut user_agent | sort | uniq -c | sort -r
Here we can see all the unique user-agents seen throughout the captured traffic preempted by how many times each of these user-agents were used!
Why sort twice?
This is an interesting problem! The uniq command does not read through an entire file and then give you unique values, it instead takes a top-down approach. Meaning, duplicate values must be directly next to each other.
Let’s take a look at an example. Here we’ve got a sample text file with three columns.
cat sample.txt
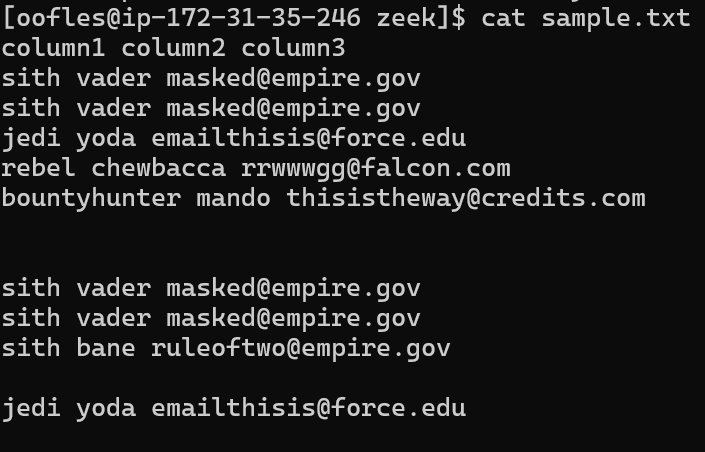
There are duplicates, so let's try and de-duplicate the file and count the results.
cat sample.txt | uniq -c
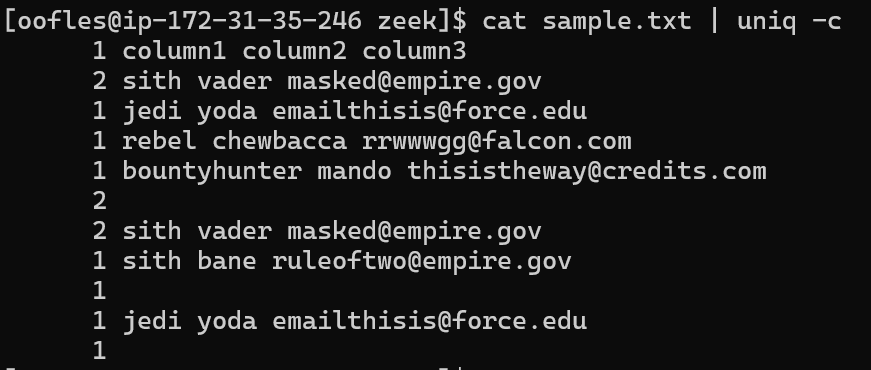
Even though Vader shows up multiple times, we still see duplicate entries because it’s only getting rid of values if they are directly next to each other. To fully emphasize the point, let’s a look when we sort it first.
cat sample.txt | sort | uniq -c
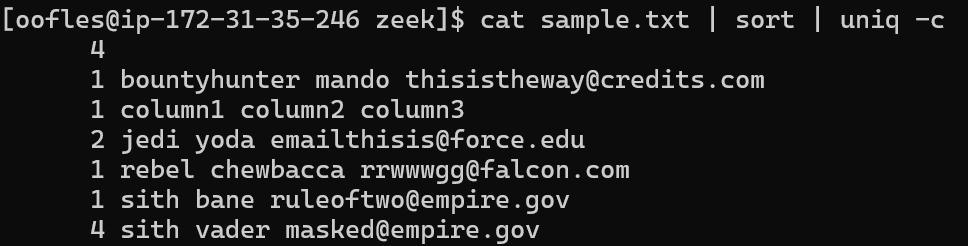
Beautiful! As your files get larger, being able to see top and bottom value counts becomes pretty important, so we'd better sort it once more at the end!
cat sample.txt | sort | uniq -c | sort
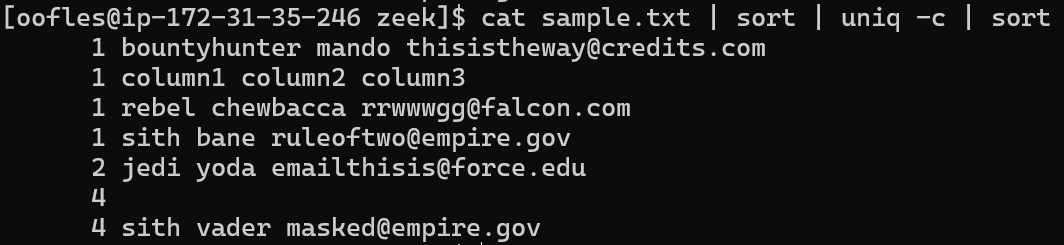
Ahhh! The Spaces and Unnecessary Lines!
You may have noticed in the previous example that the column headers and blank lines are counted in the output. Using grep and the inverse option (-v), we can get rid of those lines!
grep -v "column" = removes any lines containing the word “column”
Spaces are a bit more complicated, so without getting into regular expressions and how to format this out, I’ll just give you the syntax that works!
grep -v '^[[:space:]]*$'
All together:
cat sample.txt | grep -v "column" | grep -v '^[[:space:]]*$' | sort | uniq -c | sort

Other Examples
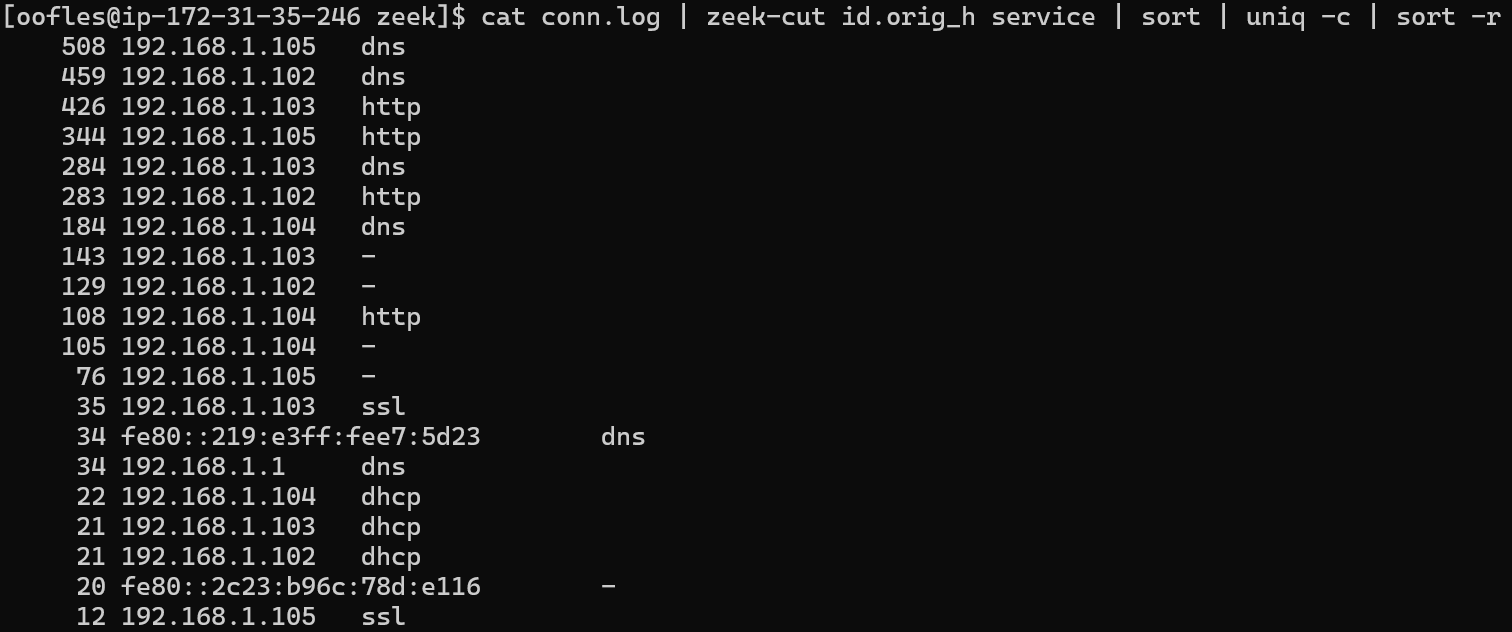
Top IPs (most conversations) seen separated by application protocol. Note: Zeek has the ability to perform port-independent protocol detection, meaning that it will identify the application protocol being used regardless if it’s being seen over the “standard” port associated with that protocol.
cat conn.log | zeek-cut id.orig_h service | sort | uniq -c | sort -r
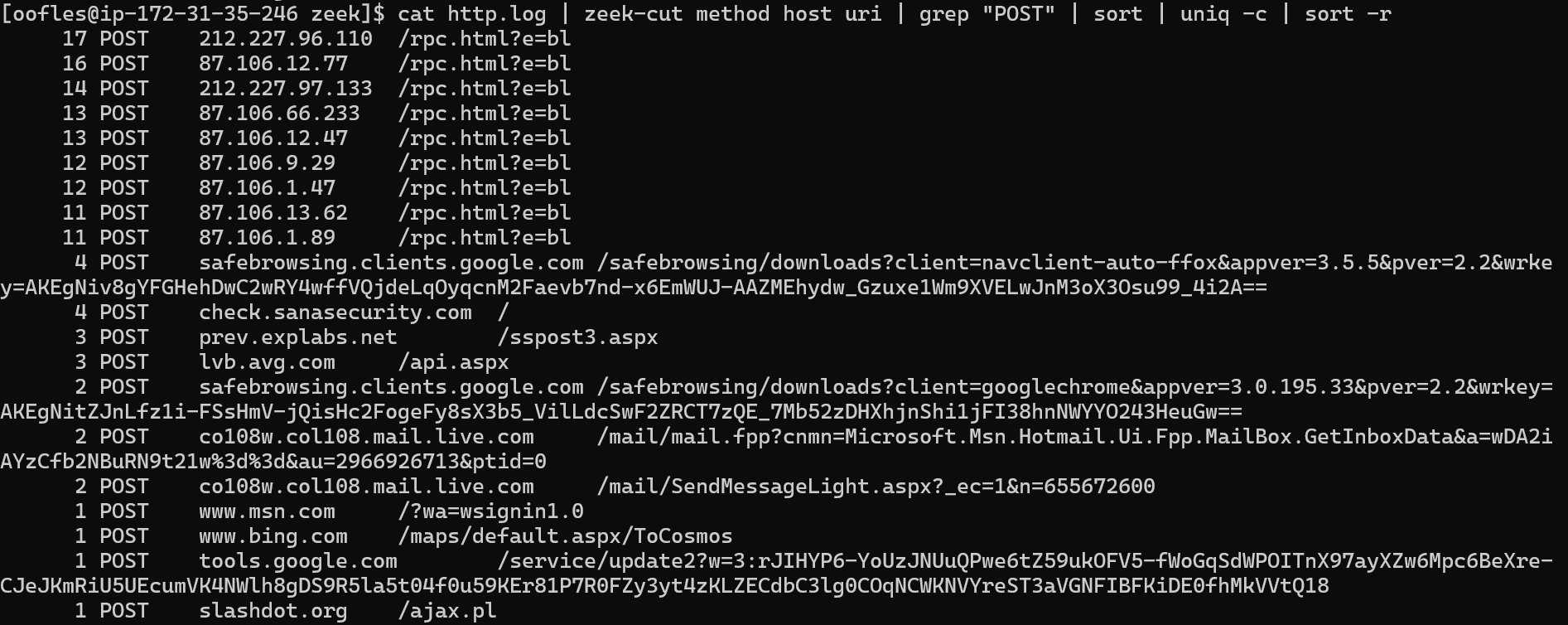
Looking for HTTP POST Methods and where that data is going.
cat http.log | zeek-cut method host uri | grep "POST" | sort | uniq -c | sort -r
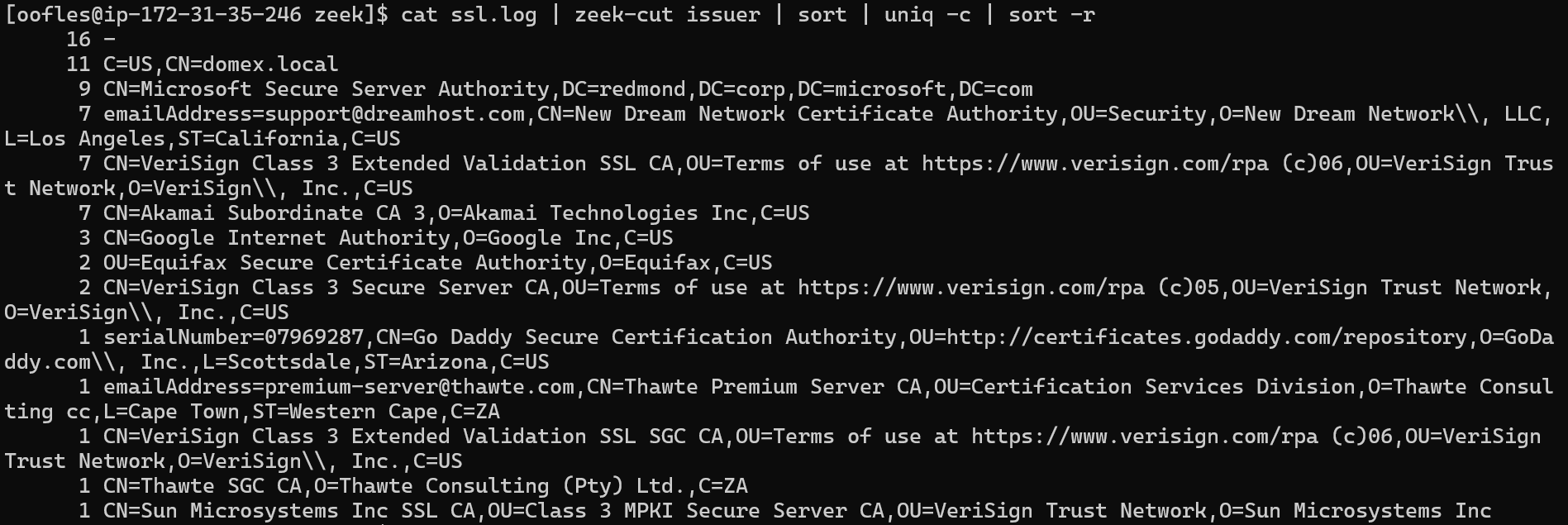
Performing long-tail analysis on TLS Certificates.
cat ssl.log | zeek-cut issuer | sort | uniq -c | sort -r